Nella prima parte abbiamo visto come creare un progetto con GSiteCrawler utilizzando il wizard automatico.
Adesso vedremo come gestire al meglio l’applicazione nel caso ci siano molti progetti in memoria.
Il programma utilizza un database di Access per conservare sia tutte le informazioni raccolte dai crawler, sia le impostazioni dei progetti.
Per capire qual è il database e dove si trova basta cliccare su File
{kind=link}
E poi “Choose database”
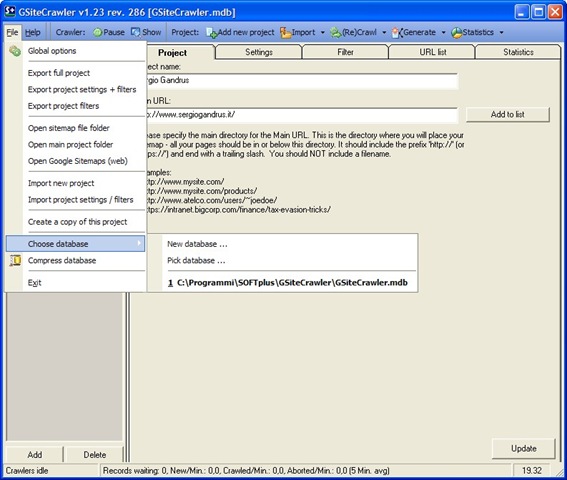{kind=link}
Vedremo che ben presto questo db diventerà sempre più ingombrante con conseguente calo delle prestazioni.
Per ovviare a questo problema possiamo adoperare l’utility di compressione
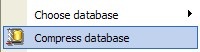{kind=link}
Generalmente la compressione salva un 20% di spazio.
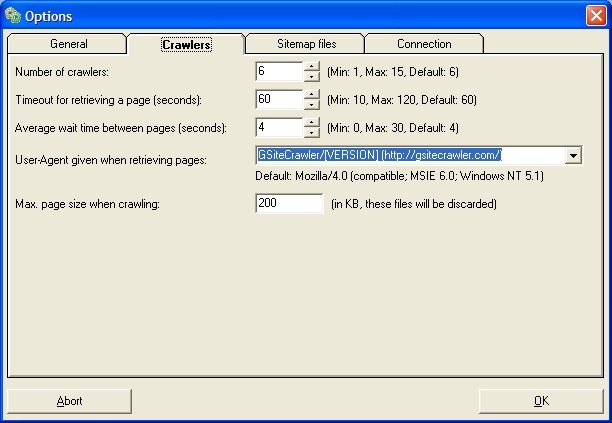
Altro trucco per ottimizzare le prestazioni di GSiteCrawler è quello di decidere quanti crawler possono funzionare contemporanemente.
Di default i crawler sono 6 ma se andiamo in File->Global Options->Crawlers
{kind=link}
{kind=link}
possiamo scegliere il numero di crawler attivi contemporaneamente. Maggiori sono capacità di elaborazione del pc e velocità della connessione, maggiore è il numero di crawler che possiamo scegliere.
Questi due post non hanno la pretesa di esaurire l’argomento sitemap con GSiteCrawler ma credo possano aver stimolato l’utilizzo del programma soprattutto in chi si avvicina al mondo SEO.
Sicuramente il problema della sitemap in formato standard adesso non sembra più tanto faticoso da risolvere.